PermonFatigue module results
For the efficient parallel solution of large-scale static elasticity or plasticity problems, we have implemented the general C interface which was designed in the previous year.
Sequential PragTic performs simulations node by node. Main idea of our first parallelization was at the node level, i.e. assigning the particular subset of nodes to every parallel process, then compute partial solutions and finally merge the results into the one result file. If we use for example 192 processor cores, then the theoretical maximum speedup would be 192. Of course, there is always the run time overhead cost so the real speedup is lower. It is caused by distributing the particular subsets of nodes at the beginning and then merging the results after the partial computations.
PermonFatigue is a module for massively parallel runs of the PragTic library, which it directly links. The Boost C++ framework is linked by our module. It is used for the C++ MPI implementation as well as for filesystem operations such as operating with work directories, copying databases, etc.
We have implemented MPI batch classes for task specification, such as loaded function, amplitudes and task distribution over computational nodes and processors.
We have created another version of the PermonFatigue module that uses the RAM disk instead of the common hard disk, so it runs faster.
We have prepared and run several benchmark tests of both PermonFatigue module versions, and determined areas where another work can be done, such as temporary buffers optimization and database copying. We have chosen a small benchmark with 120 nodes on the Salomon cluster. The loading was sin(t)+ sin(1000*t) where t means time. The resulting run times are shown in the next figure.
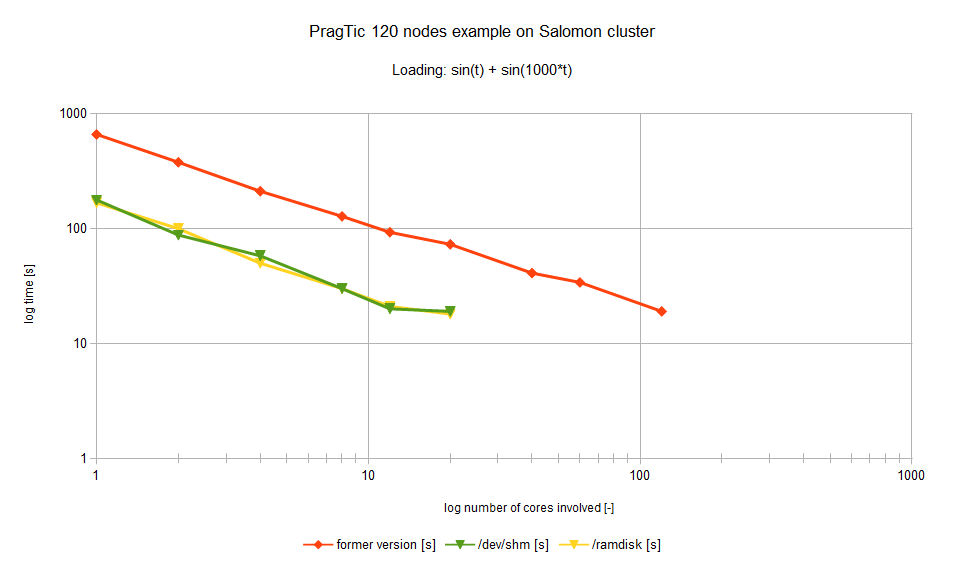
The red colour represents the run time of the version saving temporary buffers to the hard disk (former version of the PragTic), the green colour represents the run time of the version saving temporary buffers to the shared memory (/dev/shm) and the yellow colour represents the run time of the version saving temporary buffers to the RAM disk (/ramdisk). As the evaluated nodes cannot access each other’s shared memory and RAM disk, their run time graph line ends at 20 processor cores. Each Salomon’s compute node contains 24 processor cores.
By this parallelization of PragTic we have reached the speed-up of 35 on 120 processor cores. Larger speed-ups will be probably achieved once we optimize the temporary buffers and the plane and method parallelization.
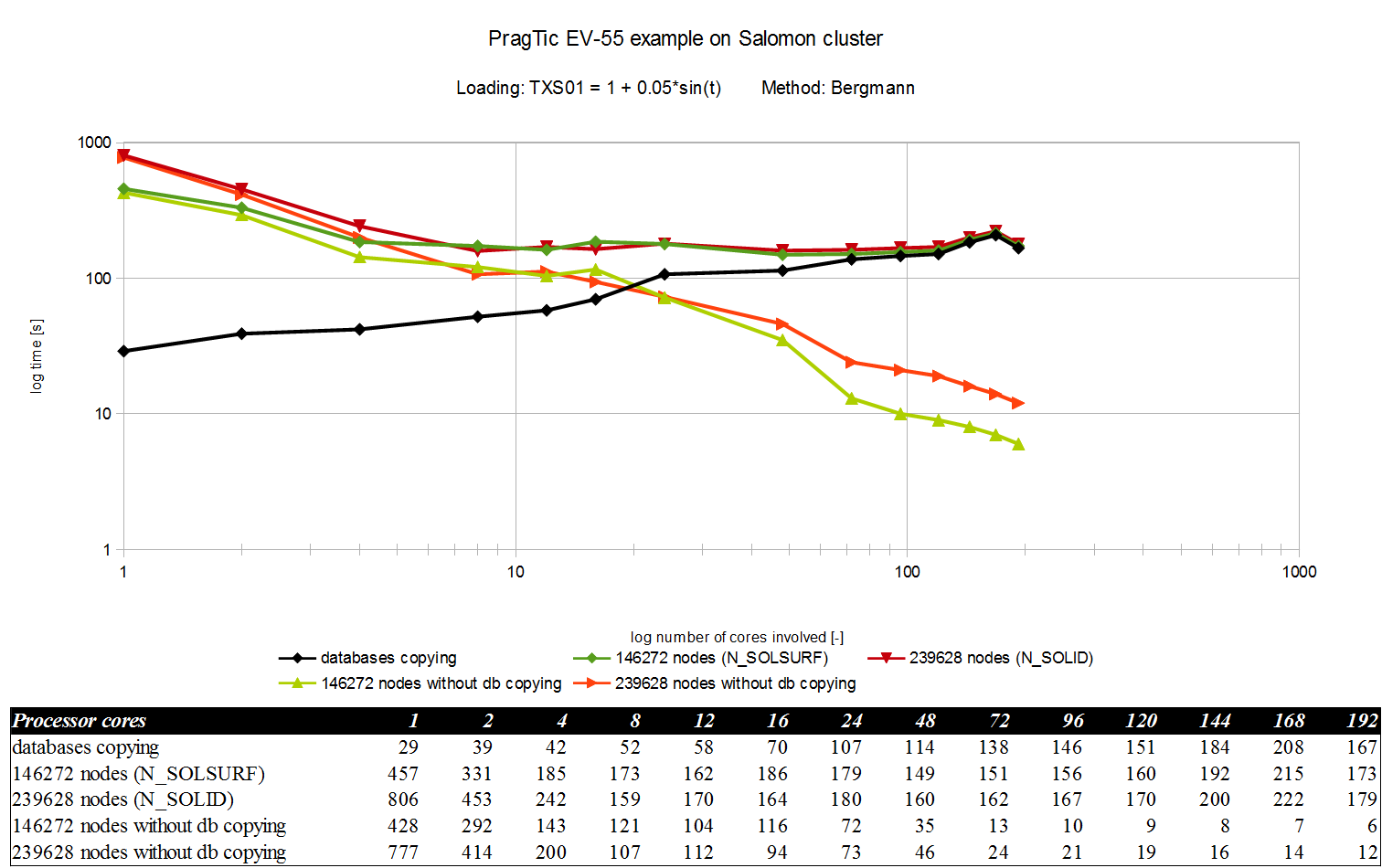
Another example was the EV-55 airplane component. The loading was 1+0.05*sin(t), representing rolling on the runway. This benchmark represents a large-scale engineering problem with the large number of nodes. We have applied the parallelization described above. However, although the times are favourable, they are significantly deteriorated by databases copying, which should be eliminated in the next year. The results are depicted in the following figure.
By the special benchmark described below, we have demonstrated that scanning more planes, at which the damage parameter is evaluated, during computational methods leads to more accurate results. An effect of the number of planes on the fatigue analysis sensitivity was demonstrated on FatLim’s benchmark. See the next figure.

The number of evaluated planes is 181 for parameter equal 30, 610 for 60, 1920 for 105 and 5268 for 180. The workload thus multiplies by 10 if we choose the reference parameter 180 instead of 60. Based on it, it can be concluded for this particular experiment that in the region 60-180 planes, the gain in precision of the fatigue index is not bigger than 1%. Results delivered for other experiments are currently analysed. Such sensitivity analysis is unique, and has not been documented for any integral method before.
The former version of PragTic is accessing disk very often during the simulations. Therefore, it wastes huge amount of the run time by writing, reading, writing, reading … etc. of partial results to/from disc. The PragTic uses files on disk as temporary buffers, causing significant slowdown of the program. These temporary buffer files are erased at the end of the run. Thus, further significant speedup can be reached by not saving the temporary buffers to the disk, but keeping them just in the memory. It is a more appropriate approach for contemporary computers and operational systems. The elimination of the temporary buffer files has been already started. It will be a hard work because this optimization requires changes at ca. 1000 lines of the PragTic's source code and their thorough testing to avoid introducing bugs.